|
Hello! I am a researcher at OpenAI, working on reinforcement learning. I received my Statistics Ph.D. from the University of Pennsylvania, gratefully advised by Edgar Dobriban, and collaborated with Eric Wong and Hamed Hassani. For my undergraduate education, I graduated from UC Berkeley, receiving Bachelor's degrees in Computer Science, Mathematics, and Statistics with honors. I was very fortunate to have been advised by William Fithian and Horia Mania. Previously, I interned at Amazon AI, working on diffusion models for causality, and at Jane Street Capital as a trading intern. |

|
|
|

|
Patrick Chao*, Edoardo Debenedetti*, Alexander Robey*, Maksym Andriushchenko*, Francesco Croce, Vikash Sehwag, Edgar Dobriban, Nicolas Flammarion, George J. Pappas, Florian Tramer, Hamed Hassani, Eric Wong arXiv | Leaderboard | Github We introduce a benchmark, automated evaluation pipeline, and leaderboard for jailbreak attacks and defenses. |
|
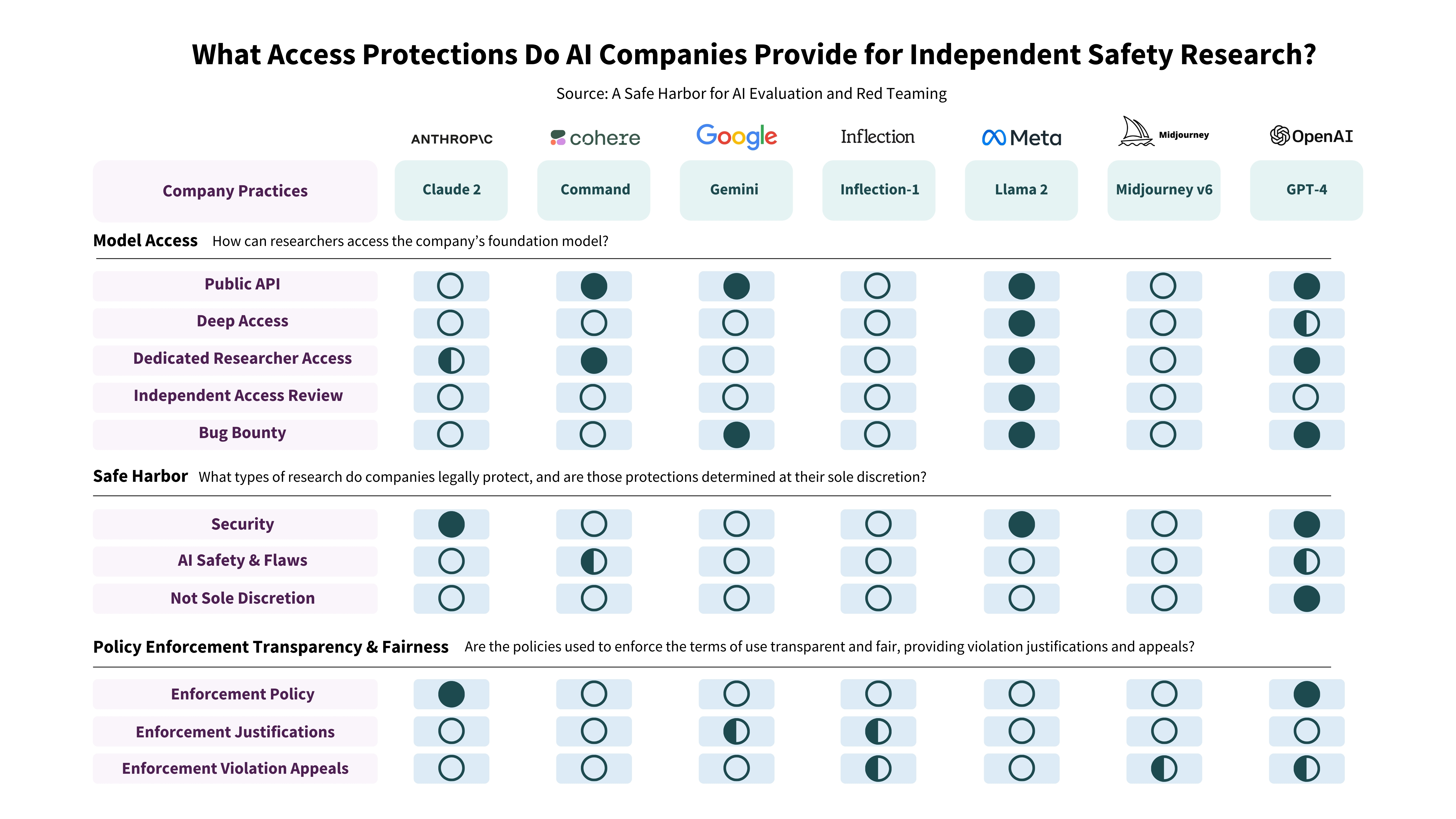
Shayne Longpre, Sayash Kapoor, Kevin Klyman, Ashwin Ramaswami, Rishi Bommasani, Borhane Blili-Hamelin, Yangsibo Huang, Aviya Skowron, Zheng-Xin Yong, Suhas Kotha, Yi Zeng, Weiyan Shi, Xianjun Yang, Reid Southen, Alexander Robey, Patrick Chao, Diyi Yang, Ruoxi Jia, Daniel Kang, Sandy Pentland, Arvind Narayanan, Percy Liang, Peter Henderson arXiv | Website | Blog We propose AI companies provide a safe harbor regarding evaluation and red teaming to promote safety, security, and trustworthiness of AI systems. |
|
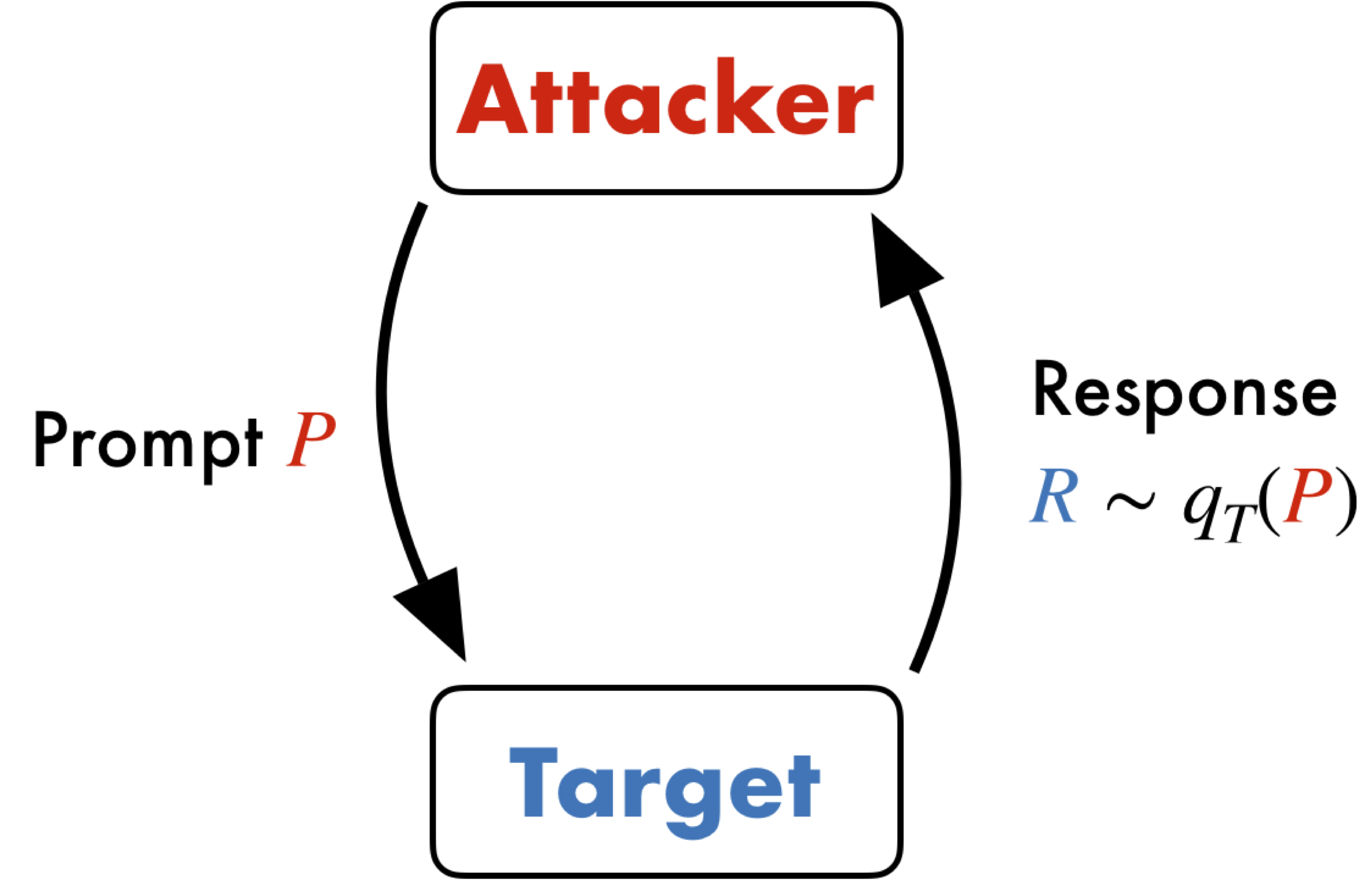
Patrick Chao, Alexander Robey, Edgar Dobriban, Hamed Hassani, George J. Pappas, Eric Wong NeurIPS Robustness of Few-shot Learning in Foundation Models 2023 arXiv | Website | Github | VentureBeat We propose PAIR, an automated method that uses a language model to systematically generate semantic jailbreaks for other language models, often in under twenty queries. PAIR is more computationally efficient than state-of-the-art methods by many orders of magnitude and only requires black-box access. |
|
Patrick Chao, Edgar Dobriban arXiv | Github When estimating an average under distribution shifts, folk wisdom is to use something robust like the median. Surprisingly, under bounded (Wasserstein) shifts, we show that the sample mean remains optimal. For linear regression, we show that ordinary least squares remains optimal. |

|
Natalie Maus*, Patrick Chao*, Eric Wong, Jacob Gardner ICML Frontiers in Adversarial Machine Learning Workshop 2023 arXiv | Blog Post | Github Systematically finding adversarial prompts for generative image models like Stable Diffusion and text models like GPT. |
|
Patrick Chao, Patrick Blöbaum, Shiva Kasiviswanathan ICML Counterfactuals in Minds & Machines Workshop 2023 (Oral) arXiv | Github Using diffusion models to answer interventional and counterfactual queries by modeling observational data, achieving state-of-the-art performance. |
|
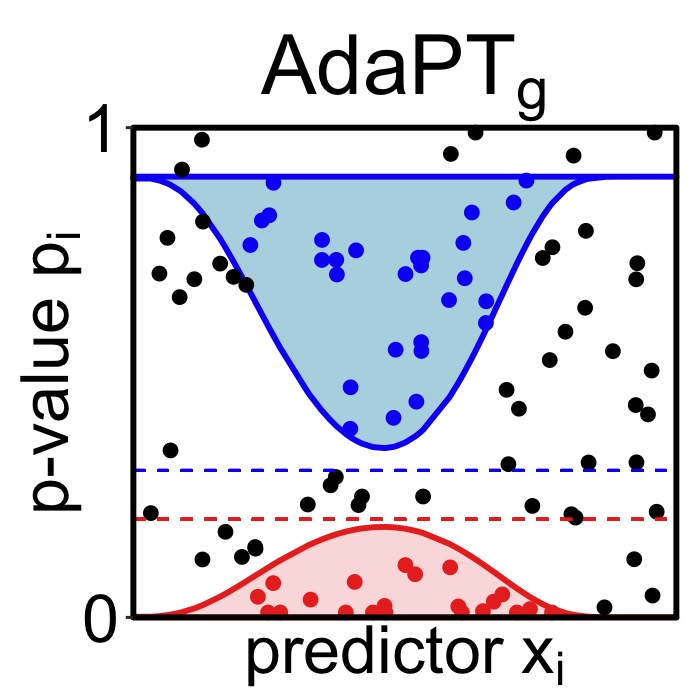
Patrick Chao, William Fithian arXiv | Vignette | Talk Recording | Github A powerful and robust multiple testing method using covariates to model the local false discovery rate by fitting a Gaussian mixture model. |
|
Patrick Chao, Jonathan Rosenberg Involve Research Journal, 2018 arXiv We show the standard definitions of conic sections are not equivalent in hyperbolic geometry and we define generalized versions. |
|
|

|
Teaching Assistant, CS189: Machine Learning, Spring
& Fall
2019
Teaching Assistant, Data 100: Principles and Techniques of Data Science, Fall 2018 |
|
Last updated Feb 2024.
|